🚢 Ship faster with git-tree based caching
TL;DR: Run CI less on your default branch by caching builds based on git tree hashes
A fairly common development workflow is the following:
- Write some code
- Open a PR
- Wait for CI
- Merge
- Wait for CI (again 🥱)
- Wait for deploy
As your team and codebase grows, build times start to creep up, suddenly CI is taking >10mins and as a consequence so are deploys – especially if you aren’t building deploy artifacts as concurrently to running your test suite.
You can speed up this process by doing the following:
- Running PR builds on a merge commit between the proposed change and the default branch.
- Caching the result of those builds based on the git tree OID (object id) – this allows for a cache key that is remains consistent no matter how you merge the changes (via rebase, squash, or merge).
Doing this will allow you to skip running tests after having merged, assuming the base branch hasn’t changed (you can enforce this behaviour by using a “Merge Queue”, which is coming natively to GitHub soon).
This can reduce your merge to deploy time significantly by allowing you to
skip many CI steps (which you’ve already run) and go straight to deploying. For
example, in a Rails project deploying to Heroku,
the majority of merges to the default branch (master in this example)
complete in around 1 min, as pictured below!
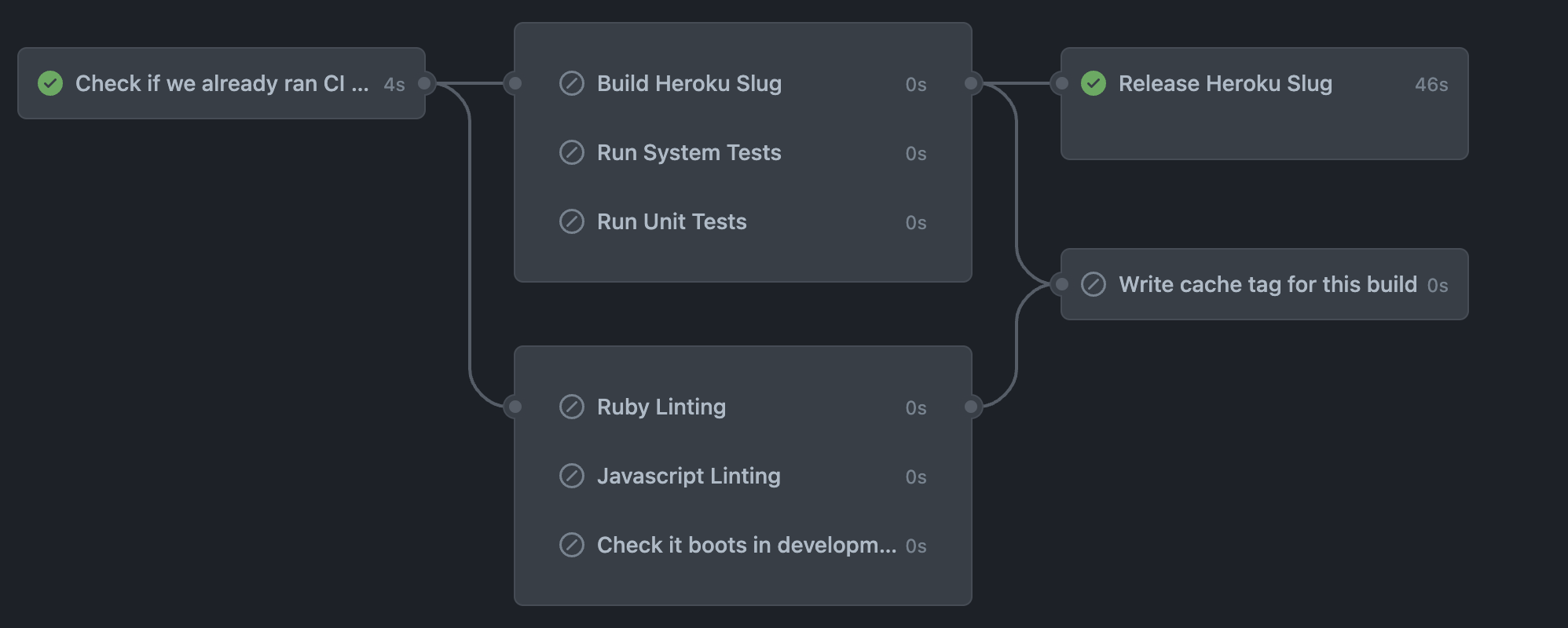
Job graph on the default branch showing prebuilding Heroku slugs (deployment artifacts) and caching CI builds.
Trees, Objects, and git
git stores a number of different types of object, most common are the
commit and tag objects. However, there are additional objects type that
git knows how to store: blob and tree.
You can read up more about these different object types in the “Pro Git” by Scott Chacon and Ben Straub, availble for free at git-scm.com/book/en/v2. In particular this section on different internal Git Objects.
A tree object, and its accompanying OID (Object ID, a 40 character SHA1 hash)
describes the directory tree of your Git repository, containing all of the
files (stored as blob objects).
Within a Git repository running the following command git rev-parse HEAD:./
will output the tree OID for the current directory. Pointing to a particular
file (e.g. git rev-parse HEAD:./README.md) will instead output the blob OID
for the file in question.
If you want to follow along yourself, here’s the set of commands that can help you explore this:
# Create a new repository
$ mkdir example-repo && cd example-repo
$ git init .
Initialized empty Git repository in /Users/christian/example-repo/.git/
# Add some content and commit it
$ touch README.md && git add . && git commit -m "README.md"
# Output the tree OID at the root of the repository
$ git rev-parse HEAD:./
f93e3a1a1525fb5b91020da86e44810c87a2d7bc
# Output the object type of the above OID
$ git cat-file -t f93e3a1a1525fb5b91020da86e44810c87a2d7bc
tree
# Output the blob OID for the ./README.md file
$ git rev-parse HEAD:./README.md
e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
# Output the object type of the above OID
$ git cat-file -t e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
blob
An important property of tree objects is that their OID will remain stable
across different commits. To illustrate, taking the above repository again, if
we ammend or rewrite the commit we made, causing the commit OID to change,
the tree ID will not.
# check the current commit OID
$ git rev-parse HEAD
f6c542f1571385c19f4b7cab6098c8dc760b5953
# rewrite the current HEAD commit
$ git commit --amend --no-edit
[main ba51625] README.md
Date: Sat Feb 26 19:20:29 2022 +0000
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 README.md
# check the current commit OID
$ git rev-parse HEAD
ba516256a926cdbdad42fb56c60177efd60cc885
# check the current tree OID
$ git rev-parse HEAD:./
f93e3a1a1525fb5b91020da86e44810c87a2d7bc
Notice while the OID of the HEAD commit changes from
f6c542f1571385c19f4b7cab6098c8dc760b5953 to
ba516256a926cdbdad42fb56c60177efd60cc885, the tree OID remains constants
across the commit rewrites as f93e3a1a1525fb5b91020da86e44810c87a2d7bc!
This is great, it can form the basis of a cache key that will persist across any merging strategy you use, whether you squash, rebase, or merge.
Pull Requests, Actions, and hidden merge commits
So great, we can get a reliable enough cache key across any merge scenario.
But, I branched a couple of hours ago and only got things cleaned up and passing now, stacks of commits have made it into our default branch since then!
Well, you’re in luck. At least when using GitHub Actions to run CI (other providers might do the same, I’m not sure) your build won’t run on the tip of your branch itself, instead it runs on a hidden merge commit between your branch and its target that GitHub creates automagically in the background every time you push to your branch.
This is why you might have noticed that for builds running on the
pull_request event in GitHub Actions, the GITHUB_SHA doesn’t match the
latest commit on your branch.
Instead, it will match the commit pointed to by refs/pull/<PR NUMBER>/merge,
you can see those commits locally (assuming you’ve configured origin as the
GitHub remote):
# list the references on the `origin` remote (GitHub)
$ git ls-remote origin
48d98993b75161e07436c1a49b92ffdc19afd805 HEAD
c2ea60b00aec9ac3d979ad8604656f07ecc2b2fc refs/heads/cga1123/amazing-changes
48d98993b75161e07436c1a49b92ffdc19afd805 refs/heads/master
c2ea60b00aec9ac3d979ad8604656f07ecc2b2fc refs/pull/1/head
c283af60b6a19f79f4810a19d3280292a7edf50a refs/pull/1/merge
# fetch the refs/pull/1/merge reference
$ git fetch origin refs/pull/1/merge
remote: Enumerating objects: 1, done.
remote: Counting objects: 100% (1/1), done.
remote: Total 1 (delta 0), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (1/1), 588 bytes | 588.00 KiB/s, done.
From github.com:CGA1123/example
* branch refs/pull/1/merge -> FETCH_HEAD
# show the commit at the head of refs/pull/1/merge
# notice how it is the merge commit between refs/heads/master and
# refs/pull/1/head (or refs/heads/cga1123/amazing-changes)
#
# this is automatically create by GitHub and also will match the SHA contained
# in the API response for this pull request under the `merge_commit_sha`
$ git show c283af60b6a19f79f4810a19d3280292a7edf50a
commit c283af60b6a19f79f4810a19d3280292a7edf50a
Merge: 48d9899 c2ea60b
Author: Christian Gregg <christian@bissy.io>
Date: Wed Feb 23 23:45:30 2022 +0000
Merge c2ea60b00aec9ac3d979ad8604656f07ecc2b2fc into 48d98993b75161e07436c1a49b92ffdc19afd805
# query the GitHub Pull Requests API for the `merge_commit_sha` attribute.
$ gh api /repos/CGA1123/example/pulls/1 --jq .merge_commit_sha
c283af60b6a19f79f4810a19d3280292a7edf50a
This mechanism is also the reason that GitHub Actions can’t run your build when
there are merge commits, if using the pull_request event! Makes sense when
you think about it, what is it supposed to run on?
This mechanism is enough if you are merging in changes quickly after having pushed the last commit and no other changes have been pushed to the target branch, it doesn’t help if it has changed though 🙁
If you are working on a repository that is quite busy and this becomes an issue, it might be worth looking into “Merge Queues” to help serialise changes landing on your default branch, ensuring that all changes are being integrated with the latest changes, which will guarantee cache hits once landing on the default branch. There are a number of solutions available and it’s coming native to GitHub soon.
Putting things together
The final step is to actually store the fact that you’ve already run a build (successfully) for a given tree and then check for that key before you run any builds, skipping any expensive operations if you have!
This assumes that your builds are idempotent and that the steps run during Pull Request builds are the same as those run after having merged. Or, that they are clearly separated, allowing you to skip the parts you’ve already run in PR.
You can store this metadata in some key-value store you have available to you,
using actions/cache, or potentially using git itself via tag objects.
Use the tree OID as part of the cache key and optionally store some metadata
in the value (potentially some identifier of the current build, for debugging).